Last week we shared our blog on Smart VDRs with you. It included some accuracy stats on Smart Summaries, the key Machine Learning tool to extract data points from transaction documentation (such as dates, locations, etc.). Before that we shared the accuracy stats of our Smart Redaction tool.
Today we would like to zoom in on these results and discuss what they mean for you.
AI powered redaction sounds good. So does fully automated redaction…
But none of that is of value if the results are not accurate: it needs to actually work. That is why, at Imprima, we share our test results with you. We seem to be unique in that. You may ask yourself why other vendors are not doing that. As one of our customers, who used Smart Redaction to redact sensitive data in their client’s data room, said: “The accuracy rates are high which was something we didn’t experience before when using other redaction tools – a welcome change indeed.”
Why is accuracy important? And what do we mean by “accuracy”?
First, let us reiterate the results we obtained:
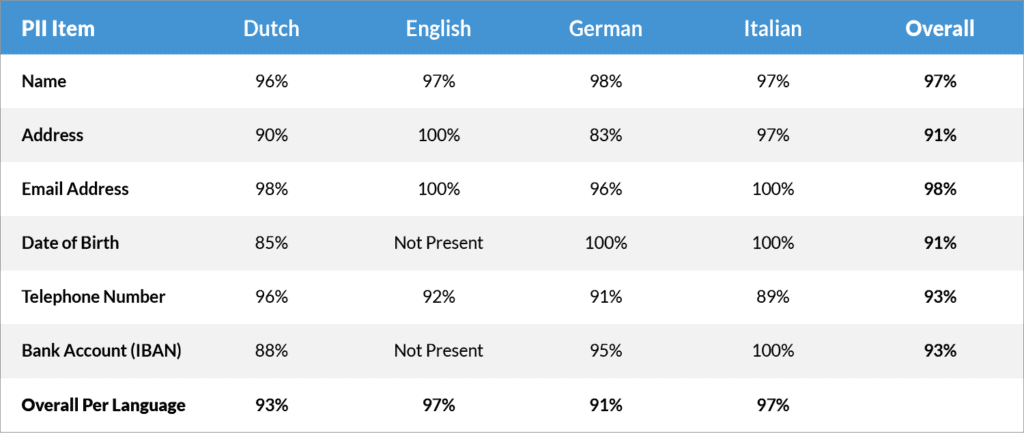
Smart Redaction test results
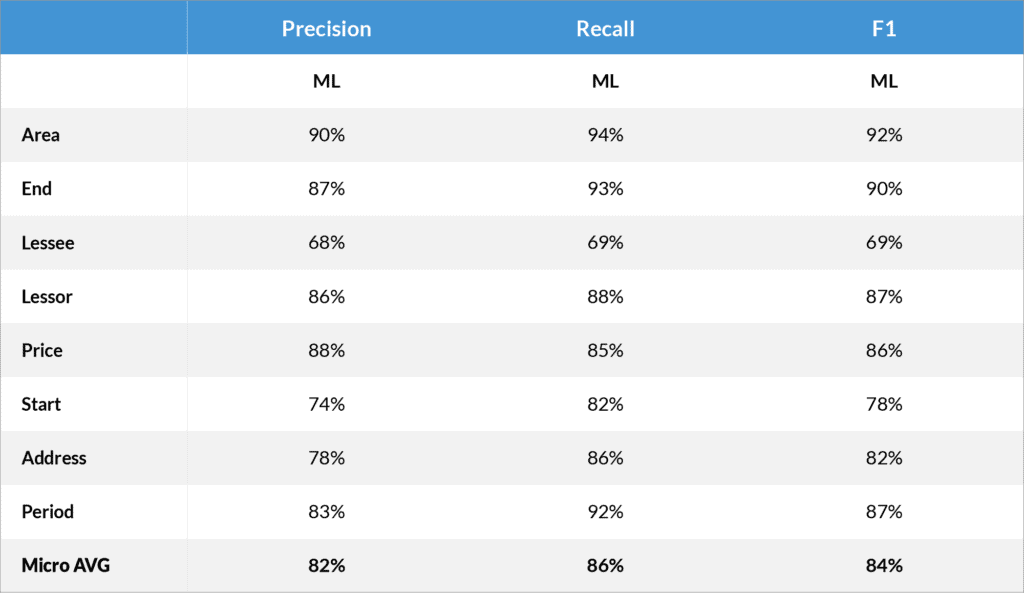
Smart Summaries test results
Accuracy – what is it, and why is it important – Saving time and increased reliability
In essence it is all about how many data points can be automatically (and correctly!) retrieved. In other words: “Recall”1.
So how does this all help you? Obviously, if – as in the above cases – around 90% of the data points are automatically extracted or redacted, then you then only have to verify and add the missing ones.
Obviously, that means that a lot of time is saved. Quoting yet another customer: ”The AI-based redaction option is an excellent tool and saved us a tremendous amount of time.” In addition, the reliability of the end results is significantly improved. Humans are not infallible, as research has shown the ability of humans to retrieve key data from documentations results in recall of only 50%-85% (according to a 2011 scientific study by Grossmann and Cormack).
Technology
The reason that we can achieve such high accuracy is that we use a Neural Net that:
- Uses the context of the key data points rather than the data points itself: only that way can it determine what the data point is about. And that context is not only used in terms of the terms (words etc.) in it, but it also looks in which order they occur, and their relevance for the key words to be extracted.
- Allows training in one language while predicting in another. Therefore, the trained data of all languages used benefits the accuracy of predicting in any language.
Ease of use
Finally, our technology is paired with – we dare say – a very slick user interface. One of our customers characterised it as “very powerful and intuitive” and further said that “it has certainly made our lives easier compared to other projects we have been involved in with other VDR providers.”
Conclusion
What conclusions might we draw? To begin with we need to acknowledge that we asked ChatGPT to review this blog, and it came up with some useful suggestions. Why are we bothering to mention that? Because it serves to prove the point that not only is AI here to stay, but it is only going to become more pervasive, forming an integral part of our daily (working) lives. Whether that be in open-source tools like ChatGPT, or in very specific, dedicated solutions like Imprima’s Smart VDR. We embrace this evolution and are committed to further developing and deploying AI to its fullest potential, helping our customers save time whilst making their lives easier.
Interested? Contact Imprima