
In recent years, many suppliers now provide what they call “AI-Redaction.” However, what are the underlying technology methods, and are some approaches better than others? “AI-redaction” is a broad term that can cover techniques such as classical machine learning (ML) models, traditional search techniques and creating lists, and regular expressions (Regex).
We’ve previously written about the particular challenges of traditional search methods for redaction. Today we dive deeper and will also look at the advantages that LLMs have over other methods.
Large Language Models (LLMs) offer some distinct advantages over Classical ML, Regex and traditional search, for redaction.
AI Redaction methods comparison summary table
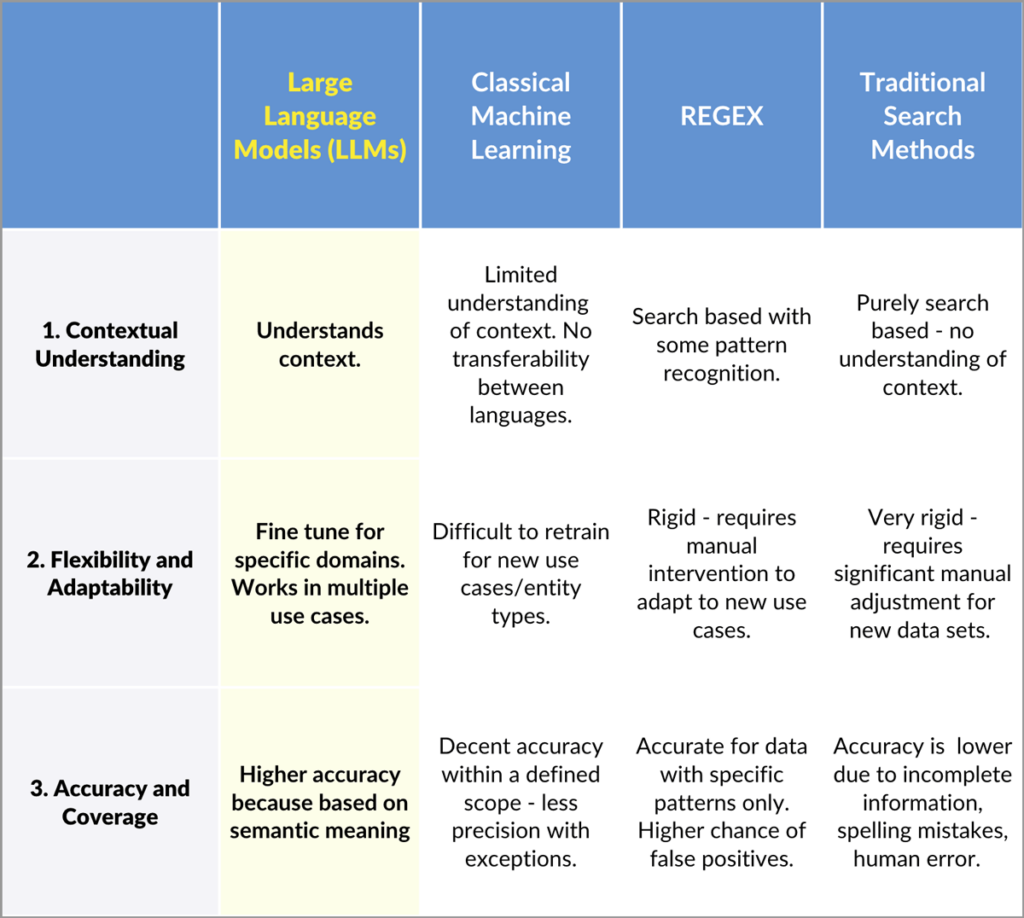
1. Contextual Understanding
Large Language Models:
One of the main strengths of LLMs is their ability to semantically understand context. They can identify sensitive information even when it does not follow a predictable pattern.
For example:
- Identifying an address or a name that is not in a standardised format.
- Recognising context-specific terms – for example, the terms “Apple” and “Amazon” as company names rely on the context of the surrounding words. Apple can also be a fruit, and Amazon can be the name of a river. Which one it is depends on the context. Also note that distinguishing between the two meanings of apple on basis of the usage of the capital A is insufficient, as the word may appear at the start of a sentence.
Classical Machine Learning Models:
Classical ML models are limited in their use of context, and have no semantical understanding. Another drawback with this approach is that for every new language you want to introduce, you must start from scratch. Note that often ML algorithms are claimed to be language independent, or language agnostic. While that is true for the algorithm itself, it is not true anymore once it is trained. LLMs, on the other hand, can predict in one language while trained in other languages. While the accuracy of the latter may be suboptimal, optimal accuracy can be obtained by fine-tuning it with a very limited amount of additional training data in the target language (much, much less than if training from scratch).
Regex:
Regex is also search based, but with the addition of patterns. Context is not used, so it still can’t understand the semantics. It can only match predefined patterns, such as email addresses or credit card numbers. This makes it effective for tasks with well-defined formats, but it will miss variations or complex entities.
Traditional Search Base Methods:
Search based methods are incapable of capturing the contextual landscape of the words that are to be redacted. For example, if you want to redact the company name Apple, you may also end up redacting every single occurrence of the word Apple, even those which are not company names, say for example an Apple Orchard.
Verdict: LLMs are superior when the redaction task requires contextual understanding, multi-lingual application or when entities vary significantly in format and context.
2. Flexibility and Adaptability
Large Language Models:
LLMs can be fine-tuned on a specific domain to extend (or limit) the scope, and generalise variations in language, domain and entity specifics, without the need for extensive training to account for these new variations.
Classical Machine Learning Models:
Classical ML can be retrained or extended, but this process is often more complex than fine-tuning an LLM. They can handle entity recognition well but may struggle to adapt quickly to new entity types without substantial retraining.
Regex:
Regex is rigid. Adapting it to new patterns requires manual rule adjustments, and it becomes increasingly complex and difficult to manage as the number of patterns grows.
Traditional Search Based Methods:
This method is also rigid and requires manual adjustment. It relies on firstly knowing which names are going to be in the dataset. However, how are you going to know which names are going to be in the data room? Moreover, you then must account for every variation (e.g., James Johnson, J. Johnson, Jim Johnson, Mr. Johnson), not to mention potential spelling errors or low-quality scans. This makes comprehensive redaction difficult. While this can be caveated with allowing users to update search-based lists on the fly, it’s not as flexible as an LLM based approach.
Verdict: LLMs have an edge in adaptability, especially in scenarios where new redaction needs may emerge over time or where flexibility is required.
3. Accuracy and Coverage
Large Language Models:
LLMs provide higher accuracy in identifying entities because they leverage vast amounts of pre-existing knowledge (they are pre-trained on generic data and can then be fine-tuned on specific data). LLMs can therefore accurately recognise entities based on their semantic meaning. For example, an LLM might recognise that a particular string is a social media handle even if it doesn’t follow a standard format.
Classical Machine Learning Models:
Classical ML models offer good accuracy within the scope they are trained for, but they can be less precise than LLMs when dealing with edge cases (exceptional cases) or entities that weren’t anticipated during training.
Regex:
Regex can be highly accurate for specific patterns but will miss information that doesn’t fit those patterns. It also has a higher chance of false positives when rules are too broad.
Traditional Search Based Methods:
As discussed above, traditional search relies on firstly knowing which names to look for. Since it is impossible to predict which names and all potential variations are going to be in the data room, it’s highly likely many names will be missed. On top of this, further complications can arise from spelling errors or low-quality scans. This makes comprehensive and accurate redaction difficult.
Verdict: While each method has certain benefits, LLMs provide the highest accuracy, coverage, and flexibility due to their ability to consider context. That said, what also can be beneficial is a combined method, allowing flexible use of each method to adapt to each methods strengths.
Conclusion
At Imprima, our Smart Redaction tool utilises LLMs to detect several diverse types of sensitive and Personally Identifiable Information and other sensitive information such as: Company Names, Person Names, Email Address, Telephone Numbers, Social Security Numbers, Passport Numbers, Date of Birth and Monetary Values. The LLM is also multi-lingual so that it can adapt to redaction across many different languages. Regex is used as pre or post-processing to eliminate certain false positives or avoid false negatives.
For AI redaction of non-language related information, Deep-Learning models are utilised.
While our technology is primarily focussed on LLMs, For AI redaction of non-language related information, Deep-Learning models are utilised. Users also have the options of uploading lists of terms to be redacted and includes the option to add Regex solutions as well. We believe that flexibility is key to a comprehensive solution.
Book a demo of Smart Redaction now to see how it works in practice.


